Most Go developers reach for channels when they need to pass data between goroutines. That instinct is usually right, but it breaks down the moment your data becomes a byte stream. File uploads, log filtering, subprocess output, streaming JSON: channels won’t help you here. Pipes will.
Go gives you two pipe primitives: io.Pipe and os.Pipe. They look similar. They are not. Using the wrong one causes subtle bugs, type errors, or deadlocks that are genuinely hard to debug. This post builds a mental model for both from first principles.
The Problem: Moving Data Without Buffering Everything
Suppose you need to download a file, hash it, and upload it to S3. The naive approach:
data, _ := ioutil.ReadAll(response.Body) // entire file in RAM
hash := sha256.Sum256(data)
upload(bytes.NewReader(data))This works fine for small files. For a 4GB video? You’ve just OOM’d your process.
The instinct to fix this is the right one, don’t buffer everything, stream it. But how?
Three Ways to Move Water
Before touching Go code, consider a concrete analogy: you have Bucket A full of water and need to get it all into Bucket B.
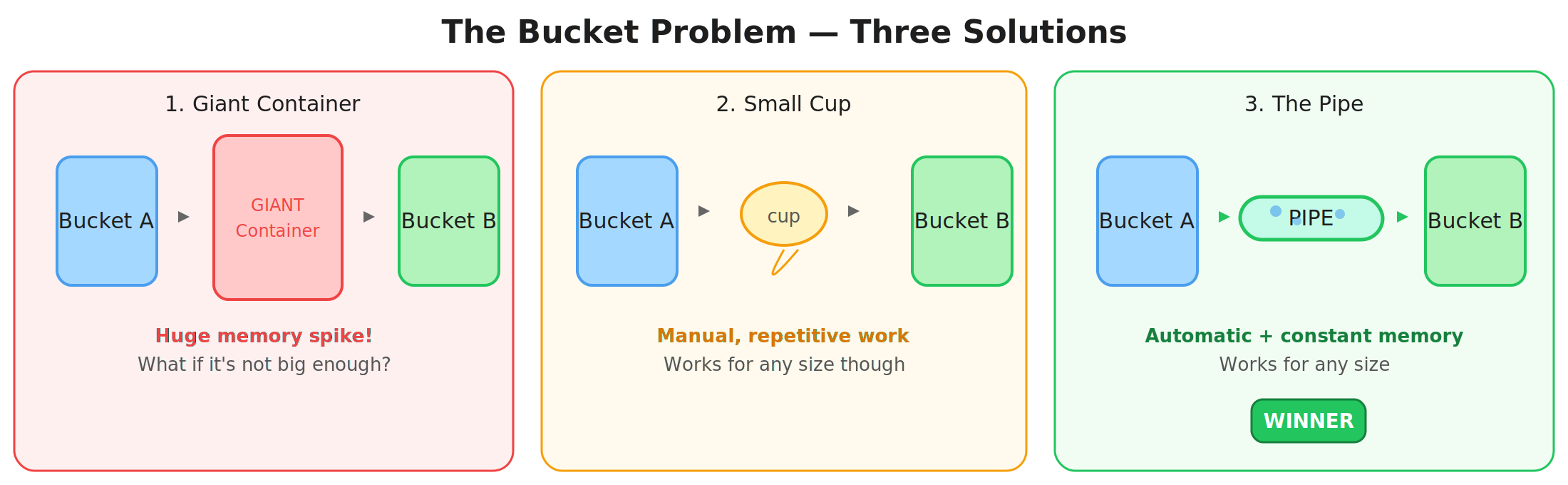
Option 1, The giant container. Pour everything from A into a massive intermediate tank, then from the tank into B. Simple, but you need a tank as big as both buckets. This is ioutil.ReadAll.
Option 2, The small cup. Fill a cup from A, walk it over, pour it into B. Repeat. Works for any size, but you’re doing the manual loop forever. This is a for { buf.Read(); process() } loop.
Option 3, A pipe. Connect A directly to B with a tube. Water flows automatically, only a small amount in the pipe at any time, and it works regardless of bucket size. This is io.Pipe.
Once you see this, you can’t unsee it. Unix shell pipes (cat file | grep error | wc -l) are the same idea. So are household plumbing and oil pipelines, continuous flow, not batch transfer.
io.Pipe: Connecting Goroutines
io.Pipe is the pure-Go pipe. It creates a synchronous, in-memory connection between a writer and a reader:
r, w := io.Pipe()You get two ends:
w(*io.PipeWriter), write data inr(*io.PipeReader), read data out
The key property: writes block until a reader is ready. There is no internal buffer. This is intentional, it enforces backpressure. The writer can never get ahead of the reader.
Because writes block, you almost always need a goroutine:
r, w := io.Pipe()
go func() {
defer w.Close() // critical, signals EOF to the reader
fmt.Fprintln(w, "hello from the other side")
}()
data, _ := io.ReadAll(r)
fmt.Println(string(data)) // "hello from the other side"The Most Common Mistake
Forgetting w.Close():
go func() {
w.Write([]byte("data"))
// missing w.Close()
}()
io.Copy(os.Stdout, r) // hangs forever, reader waits for EOF that never comesThe reader has no way to know the writer is done unless it closes the pipe. Close() sends the EOF signal. Make it a habit to use defer w.Close() at the top of your goroutine.
The Real Use Case: Streaming Without Buffers
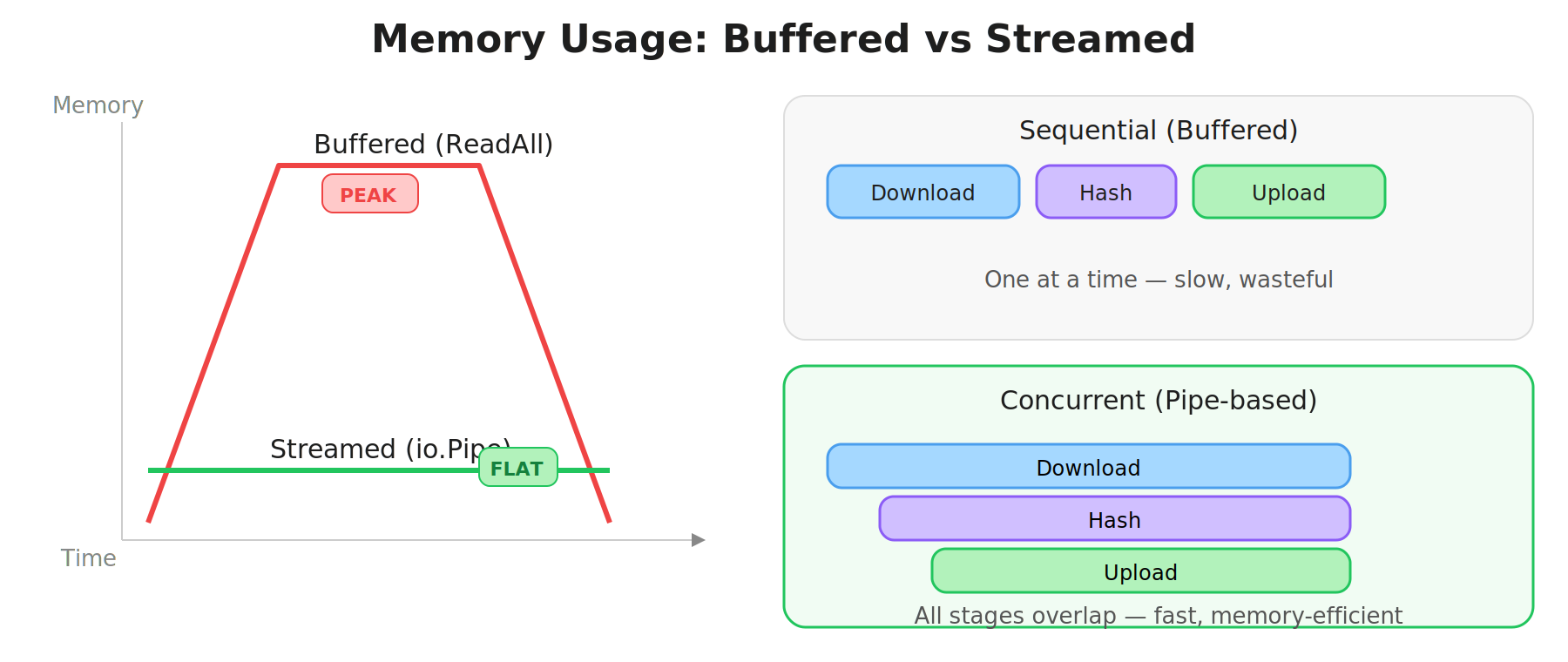
Here’s the file upload scenario solved with io.Pipe:
r, w := io.Pipe()
go func() {
defer w.Close()
resp, _ := http.Get(largeFileURL)
defer resp.Body.Close()
io.Copy(w, resp.Body)
}()
// Hash and upload happen simultaneously as data flows through
hasher := sha256.New()
tee := io.TeeReader(r, hasher)
uploadToS3(tee)
fmt.Printf("SHA256: %x\n", hasher.Sum(nil))Download, hashing, and upload are all in flight at the same time. Memory usage stays flat regardless of file size.
Propagating Errors Across Goroutines
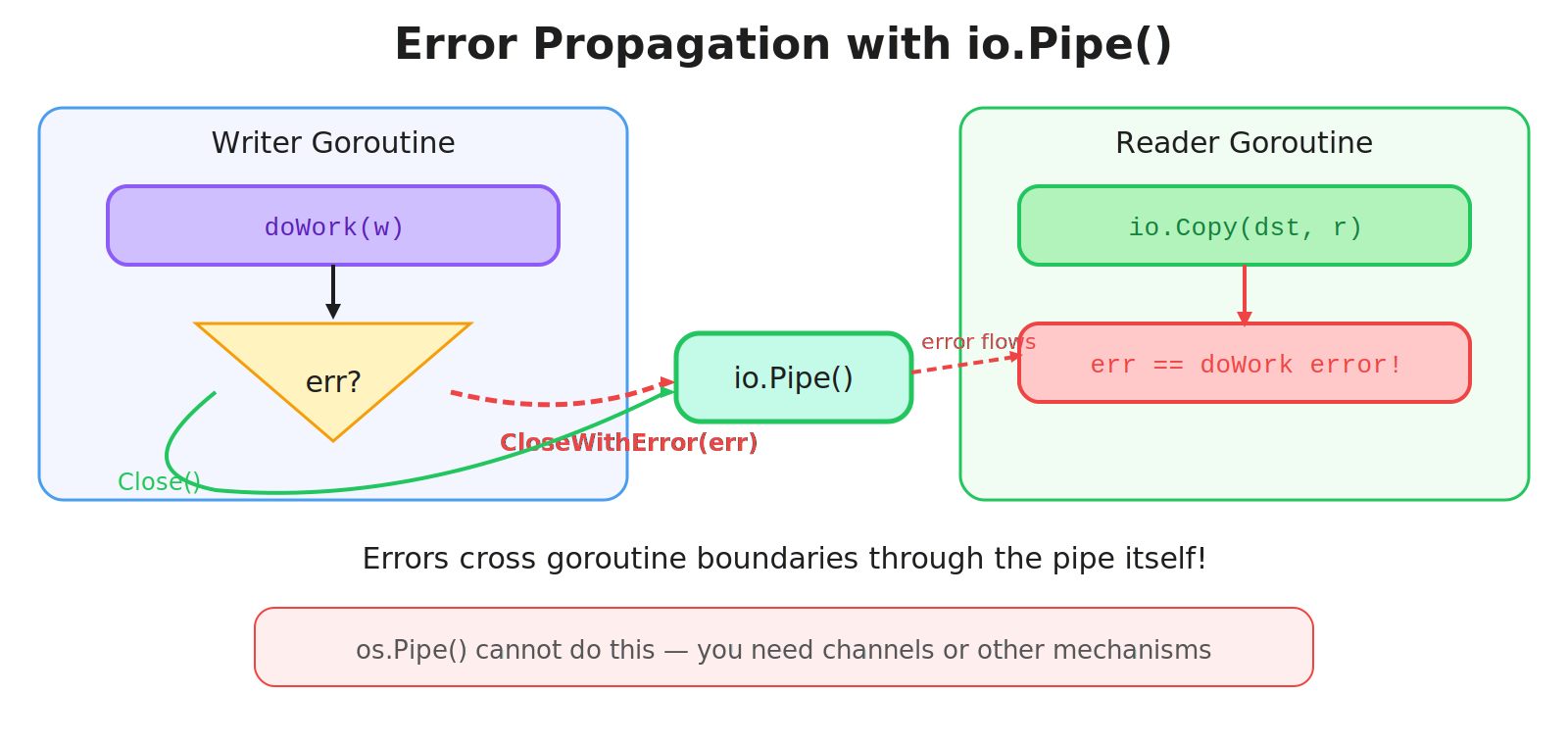
This is io.Pipe’s underrated superpower. If your writer goroutine encounters an error, it can ship that error to the reader:
r, w := io.Pipe()
go func() {
if err := streamFromUpstream(w); err != nil {
w.CloseWithError(fmt.Errorf("upstream failed: %w", err))
return
}
w.Close()
}()
_, err := io.Copy(destination, r)
if err != nil {
// err is exactly what was passed to CloseWithError
log.Printf("pipeline failed: %v", err)
}No channels, no sync.WaitGroup, no shared variables. The error rides the pipe.
os.Pipe: Crossing the Process Boundary
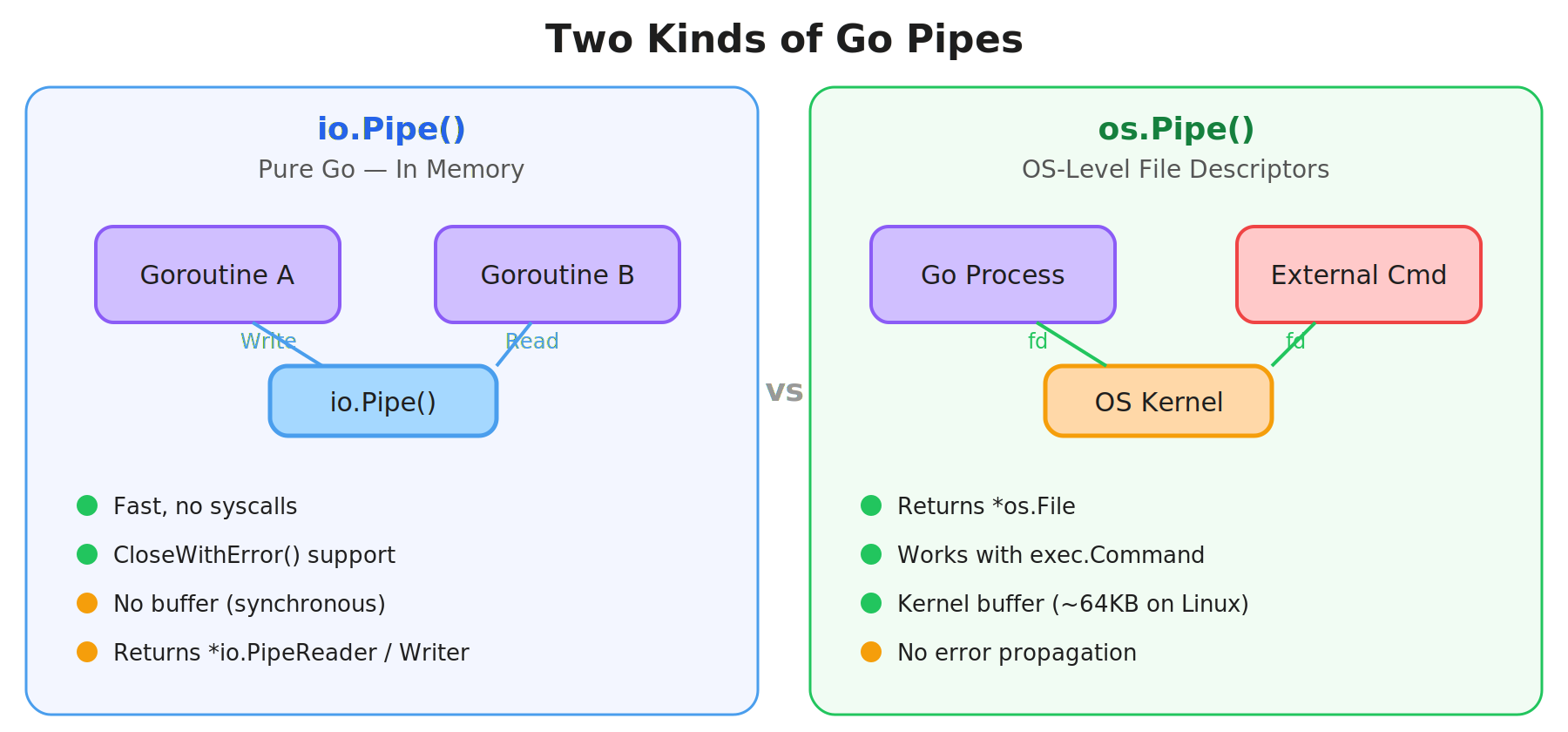
os.Pipe is a different beast:
r, w, err := os.Pipe()Instead of io.PipeReader/io.PipeWriter, you get two *os.File values backed by real OS file descriptors. This is not an in-memory abstraction, it’s a kernel pipe.
Why does that matter? Because the OS cares about file descriptors. External processes, exec.Command, and low-level syscalls all speak in file descriptors, not io.Reader/io.Writer interfaces.
The Problem io.Pipe Can’t Solve
Try to pipe into an external command using io.Pipe:
r, w := io.Pipe()
cmd := exec.Command("grep", "ERROR")
cmd.Stdout = w // compiles, but the subprocess gets a file descriptor ,
// io.Pipe doesn't have one, so subprocess I/O won't workIt’s subtler than a type error, exec.Command.Stdout accepts io.Writer, so io.Pipe satisfies it at the type level. But the subprocess itself gets a file descriptor, and io.Pipe doesn’t have one. For subprocess I/O, you need os.Pipe.
Capturing Subprocess Output
r, w, _ := os.Pipe()
cmd := exec.Command("go", "test", "./...")
cmd.Stdout = w
cmd.Stderr = w
cmd.Start()
w.Close() // close writer in parent so reading doesn't block after cmd exits
output, _ := io.ReadAll(r)
cmd.Wait()
fmt.Println(string(output))Note the w.Close() after cmd.Start(), the parent process must close its copy of the write end, otherwise io.ReadAll on the read end will block even after the child exits (the OS sees the write end still open and won’t send EOF).
The Classic Testing Trick: Capturing os.Stdout
func captureStdout(fn func()) string {
old := os.Stdout
r, w, _ := os.Pipe()
os.Stdout = w
fn()
w.Close()
os.Stdout = old
out, _ := io.ReadAll(r)
return string(out)
}
output := captureStdout(func() {
fmt.Println("this gets captured")
})
// output == "this gets captured\n"This is essential for testing CLI tools and functions that write directly to stdout.
The Key Difference: Buffering
This trips people up constantly.
io.Pipe has zero internal buffer. Every write blocks until a reader consumes it. If you write without a goroutine running the reader simultaneously, you deadlock immediately:
r, w := io.Pipe()
w.Write([]byte("data")) // deadlock, no reader is running yet
io.ReadAll(r)os.Pipe has an OS-managed buffer (typically 64KB on Linux). Writes succeed immediately until the buffer fills. This feels more forgiving, but it means you can silently drop errors if the buffer fills and you’re not draining it.
r, w, _ := os.Pipe()
w.Write([]byte("data")) // fine, goes into OS buffer
w.Close()
out, _ := io.ReadAll(r) // drains the bufferThe practical rule: with io.Pipe, always put the writer in a goroutine. With os.Pipe, it’s more lenient, but you still need to drain the reader before the buffer fills.
Chaining Pipes: Shell-Style Pipelines in Go
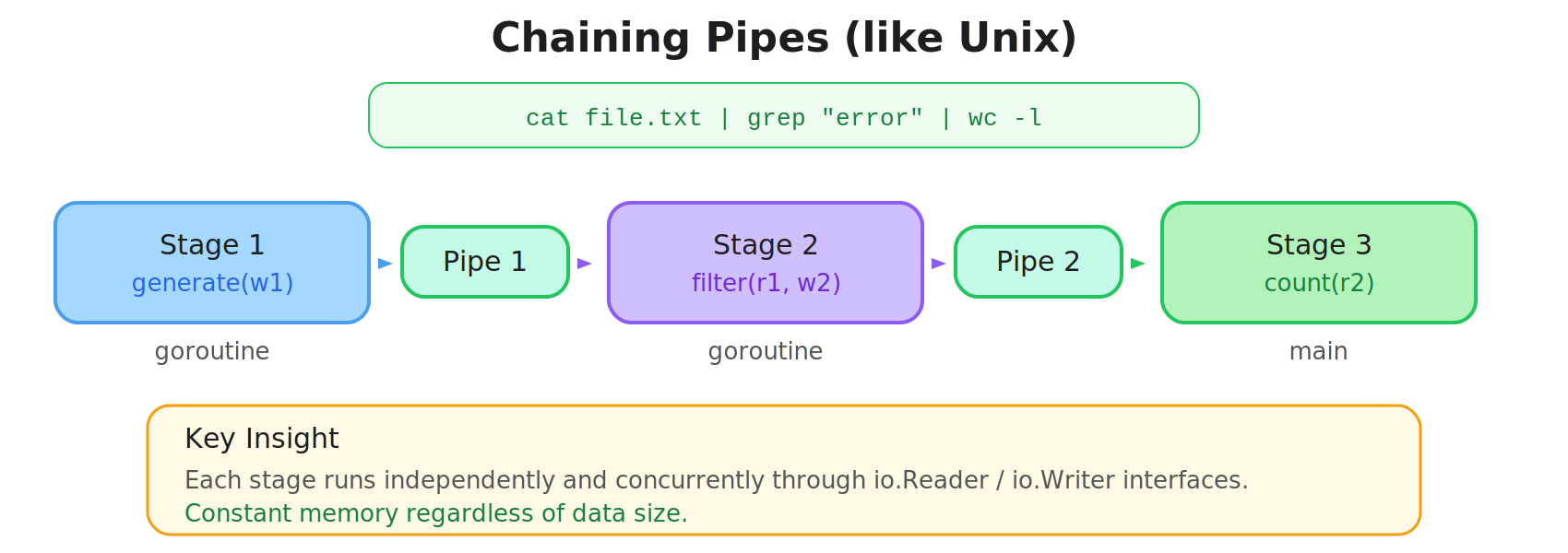
One of the more powerful patterns is chaining pipes to build multi-stage processing:
r1, w1 := io.Pipe()
r2, w2 := io.Pipe()
// Stage 1: generate log lines
go func() {
defer w1.Close()
for _, line := range logSource() {
fmt.Fprintln(w1, line)
}
}()
// Stage 2: filter for errors only
go func() {
defer w2.Close()
scanner := bufio.NewScanner(r1)
for scanner.Scan() {
if strings.Contains(scanner.Text(), "ERROR") {
fmt.Fprintln(w2, scanner.Text())
}
}
}()
// Stage 3: count and print
scanner := bufio.NewScanner(r2)
count := 0
for scanner.Scan() {
fmt.Println(scanner.Text())
count++
}
fmt.Printf("\n%d errors found\n", count)This is exactly what cat file | grep ERROR | wc -l does in shell, except now it’s in Go, type-safe, and each stage runs concurrently.
Pipes vs Channels
The question comes up constantly. The answer is: they solve different problems.
Use channels when you’re passing discrete, structured values between goroutines:
ch := make(chan User)
go func() { ch <- fetchUser(id) }()
user := <-chUse pipes when you’re working with byte streams or anything that implements io.Reader/io.Writer:
r, w := io.Pipe()
go func() {
defer w.Close()
json.NewEncoder(w).Encode(users)
}()
json.NewDecoder(r).Decode(&result)The reason pipes win for I/O: the entire Go standard library speaks io.Reader and io.Writer. Compression, encryption, HTTP bodies, file I/O, hashing, they all compose seamlessly through pipes. Channels would require you to buffer and serialize everything manually.
Quick Reference
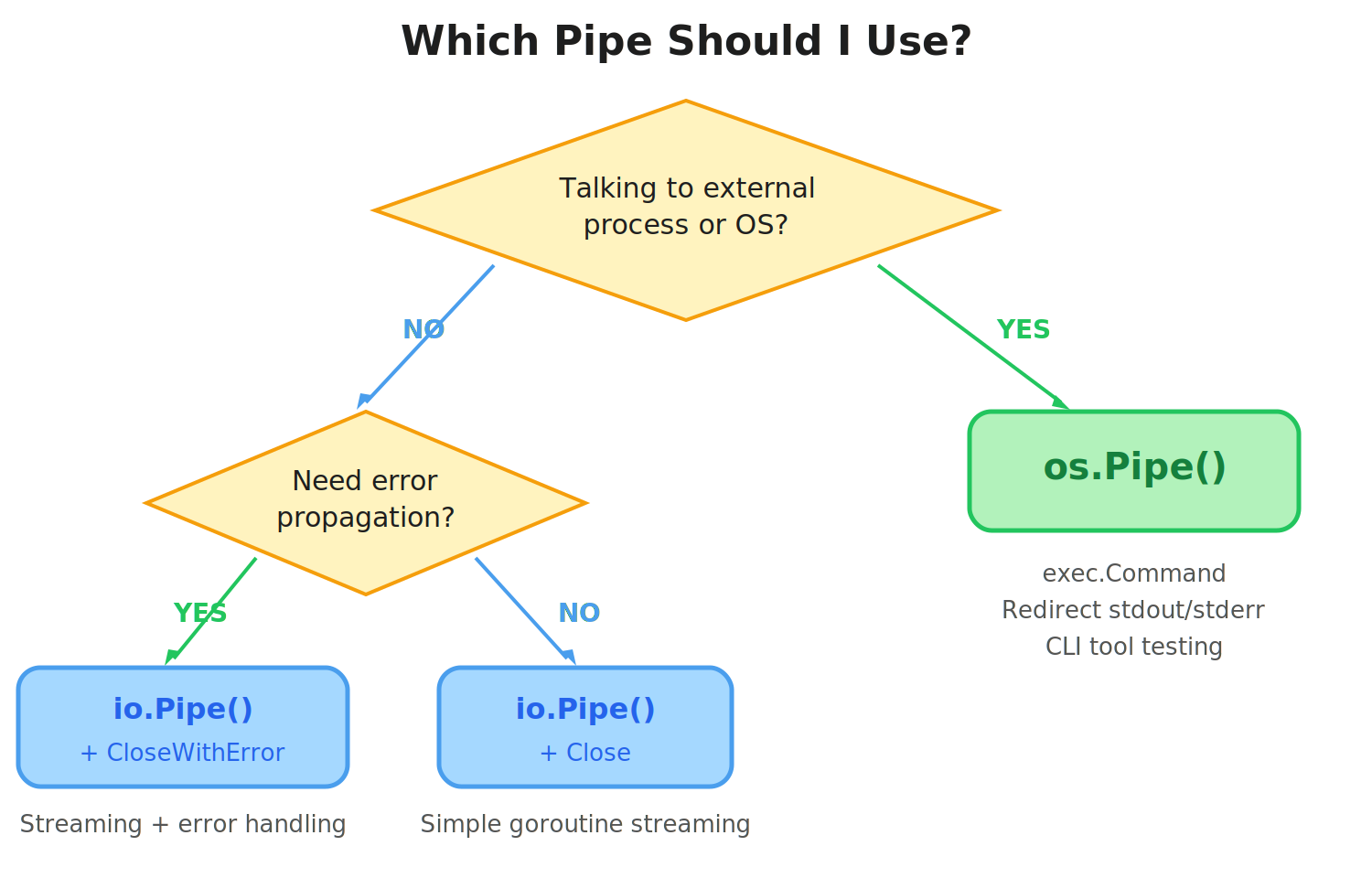
| Scenario | Use |
|---|---|
| Stream between goroutines | io.Pipe() |
| Subprocess stdout/stderr | os.Pipe() |
Capture os.Stdout in tests | os.Pipe() |
| Propagate errors across pipe | io.Pipe() + CloseWithError |
| Chain I/O transformations | io.Pipe() |
Pass to exec.Command | os.Pipe() |
| Maximum throughput, no syscall overhead | io.Pipe() |
The Three Rules
If you take nothing else from this post:
io.Pipe= Go ↔ Go. Pure memory, zero buffer, always needs a goroutine on the write side.os.Pipe= Go ↔ OS. Real file descriptors, small OS buffer, required for subprocess I/O.- Always
defer w.Close(). On both types. A pipe without a close is a deadlock waiting to happen.
Streaming bytes? Use pipes. OS involved? os.Pipe. Only Go? io.Pipe. Everything composes through io.Reader and io.Writer, that’s the whole game.